Steps: [ install | jax | haiku | q-learning | dqn | ppo | next_steps ]
Q-Learning on FrozenLake¶
In this first reinforcement learning example we’ll solve a simple grid world environment.
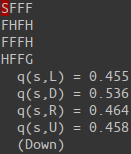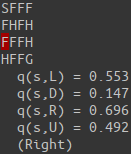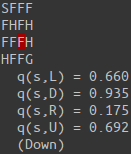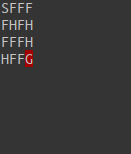
Our agent starts at the top left cell, labeled S. The goal of our agent is to find its way to the bottom right cell, labeled G. The cells labeled H are holes, which the agent must learn to avoid.
In this example, we’ll implement a simple value-based agent, which we update using the q-learning algorithm.
To run this, either hit the Google Colab button or download and run the script on your local machine.
import coax
import gymnasium
import jax
import jax.numpy as jnp
import haiku as hk
import optax
# the MDP
env = gymnasium.make('FrozenLakeNonSlippery-v0')
env = coax.wrappers.TrainMonitor(env)
def func(S, A, is_training):
value = hk.Sequential((hk.Flatten(), hk.Linear(1, w_init=jnp.zeros), jnp.ravel))
X = jax.vmap(jnp.kron)(S, A) # S and A are one-hot encoded
return value(X)
# function approximator
q = coax.Q(func, env)
pi = coax.BoltzmannPolicy(q, temperature=0.1)
# experience tracer
tracer = coax.reward_tracing.NStep(n=1, gamma=0.9)
# updater
qlearning = coax.td_learning.QLearning(q, optimizer=optax.adam(0.02))
# train
for ep in range(500):
s, info = env.reset()
for t in range(env.spec.max_episode_steps):
a = pi(s)
s_next, r, done, truncated, info = env.step(a)
# small incentive to keep moving
if jnp.array_equal(s_next, s):
r = -0.01
# update
tracer.add(s, a, r, done or truncated)
while tracer:
transition_batch = tracer.pop()
qlearning.update(transition_batch)
if done or truncated:
break
s = s_next
# early stopping
if env.avg_G > env.spec.reward_threshold:
break
# run env one more time to render
s, info = env.reset()
env.render()
for t in range(env.spec.max_episode_steps):
# print individual state-action values
for i, q_ in enumerate(q(s)):
print(" q(s,{:s}) = {:.3f}".format('LDRU'[i], q_))
a = pi.mode(s)
s, r, done, truncated, info = env.step(a)
env.render()
if done or truncated:
break
if env.avg_G < env.spec.reward_threshold:
name = globals().get('__file__', 'this script')
raise RuntimeError(f"{name} failed to reach env.spec.reward_threshold")