FrozenLake with PPO¶
In this notebook we solve a non-slippery version of the FrozenLake-v0 environment using the TD actor critic algorithm with
PPO policy updates.
We’ll use a linear function approximator for our policy \(\pi_\theta(a|s)\) and our state value function \(v_\theta(s)\). Since the observation space is discrete, this is equivalent to the table-lookup case.
import coax
import jax
import jax.numpy as jnp
import gymnasium
import haiku as hk
import optax
# the MDP
env = gymnasium.make('FrozenLakeNonSlippery-v0')
env = coax.wrappers.TrainMonitor(env)
def func_v(S, is_training):
value = hk.Sequential((hk.Linear(1, w_init=jnp.zeros), jnp.ravel))
return value(S)
def func_pi(S, is_training):
logits = hk.Linear(env.action_space.n, w_init=jnp.zeros)
return {'logits': logits(S)}
# function approximators
pi = coax.Policy(func_pi, env)
v = coax.V(func_v, env)
# create copies
pi_old = pi.copy() # behavior policy
v_targ = v.copy() # target network
# experience tracer
tracer = coax.reward_tracing.NStep(n=1, gamma=0.9)
# updaters
simple_td = coax.td_learning.SimpleTD(v, v_targ, optimizer=optax.adam(0.02))
ppo_clip = coax.policy_objectives.PPOClip(pi, optimizer=optax.adam(0.01))
# train
for ep in range(500):
s, info = env.reset()
for t in range(env.spec.max_episode_steps):
a, logp = pi_old(s, return_logp=True)
s_next, r, done, truncated, info = env.step(a)
# small incentive to keep moving
if jnp.array_equal(s_next, s):
r = -0.01
# update
tracer.add(s, a, r, done, logp)
while tracer:
transition_batch = tracer.pop()
_, td_error = simple_td.update(transition_batch, return_td_error=True)
ppo_clip.update(transition_batch, td_error)
# sync target networks
v_targ.soft_update(v, tau=0.01)
pi_old.soft_update(pi, tau=0.01)
if done or truncated:
break
s = s_next
# early stopping
if env.avg_G > env.spec.reward_threshold:
break
# run env one more time to render
s, info = env.reset()
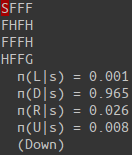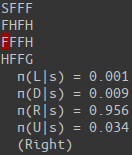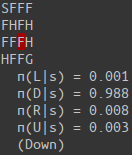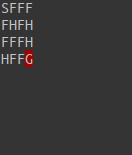
env.render()
for t in range(env.spec.max_episode_steps):
# estimated state value
print(" v(s) = {:.3f}".format(v(s)))
# print individual action probabilities
params = pi.dist_params(s)
propensities = jax.nn.softmax(params['logits'])
for i, p in enumerate(propensities):
print(" π({:s}|s) = {:.3f}".format('LDRU'[i], p))
a = pi.mode(s)
s, r, done, truncated, info = env.step(a)
env.render()
if done or truncated:
break
if env.avg_G < env.spec.reward_threshold:
name = globals().get('__file__', 'this script')
raise RuntimeError(f"{name} failed to reach env.spec.reward_threshold")